L3 fabric DC -The underlay Network (BGP) -part2
In the previous post, we laid the foundation of L3 fabric DC
In this post we will discuss the underlay network which mainly provide IP reachability plus ECMP capability, here BGP would play a role in your DC next to the 3 other that we discussed one of the previous posts.
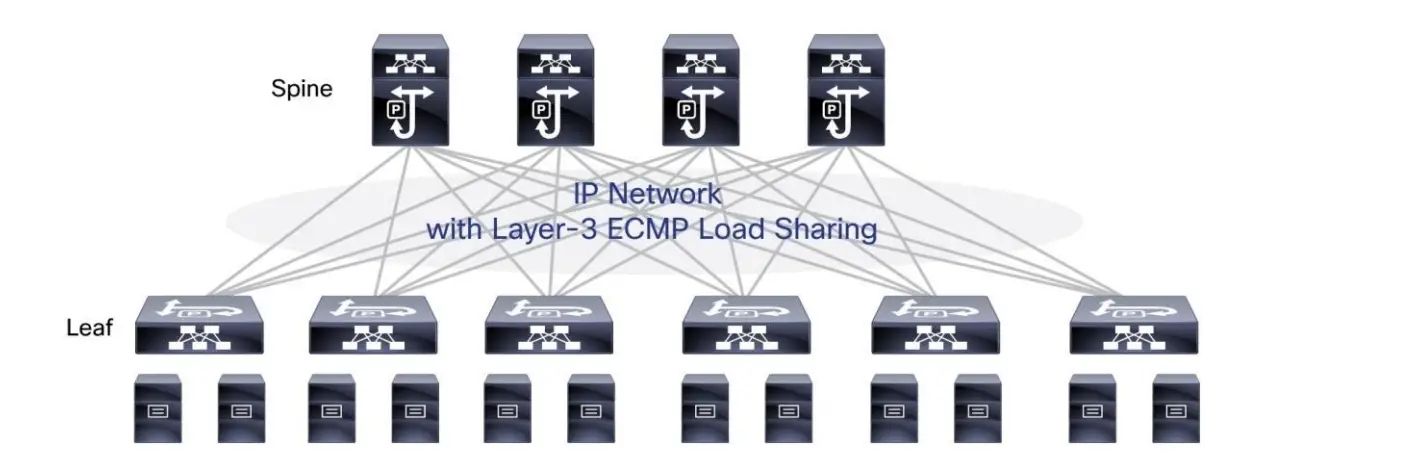
For the sake of simplicity think of this L3 fabric like group of routers connected physically in spine and leaf topology (3 stages CLOS leaf-spine-leaf), our target is to provide IP connectivity.
How many Leaf/TOR you would have? This might vary based on the size of your DCs some would have 10 some would have more than 2000 some DCs would have even 5 stage CLOS.
Then the question would be
Which routing protocol you would chose?
you can build any network using these options Static, RIP, EIGRP, ISIS, OSPF, BGP for sure static is out of the questions from the perspective of scaling specially at the spine even if you say let's configure default static with N number of next hops in the leaf where N is the number of spines. But when it come to the spine you would have to create thousands of static routes in each spine and if we run static we would face all the issue that static route faced like black-holing.
finally what about the 5 stages CLOS ?
so static route for sure is not our friend in building the underlay network.
What are our other options? RIP, EGRIP, ISIS, OSPF, BGP.
RIP really !! RIP that’s so old and slow, some would recall RIP as “Rest In Peace”
EIGRP is another option but even after Cisco made it open standard, still JUNIPER, Arista and other vendors might not support it at least for political reasons. So running it make you bounded with one vendor or excluding some others. Remember one of the main of benefits of L3 fabric is being open standard.
ISIS or OSPF I won't go for the endless debates between ISIS Versus OSPF as from the perspective of DC underlay network it won't make big different so for the sake simplicity I will say IGP in DC is either ISIS or OSPF for underlay network (OSPF may more popular in here).
So now the comparison had become, IGP (OSPF or ISIS) versus BGP.
If you look at it from the perspective of scalability we can just say that BGP is the chosen protocol to run the internet so what can scale for more than 400K internet route can scale to carry your few thousand DC routes.
Also, BGP is richer than any IGP in its capability to tag routes (community) as well its policy to filter prefixes.
I am not saying that BGP always wins in here, in fact many consultants would go for OSPF but I am saying it is the trend even for the smaller DC and for sure the best practices for massive DC.
Two factors you need to consider when running BGP in comparison to IGP.
- Your TOR is likely more to support IGP than BGP although nowadays most of TOR would but it is a factor to be considered.
- BGP doesn’t like load balancing by nature so you have to adjust it for that. However any IGP actively load balance once it found ECMP (either by default CISCO, to be configured JUNIPER), which is not the case for BGP as if you remember the long list selection mechanism that BGP use to finally select one and only one next hope, in another word BGP is by nature not for ECMP but IGP is totally for it.
Why do we care that much about ECMP?
It is super important part of the spine and leaf physical connectivity where we want the leaf to load balance the traffic over all the existing spines so when we run BGP we have to make sure that the traffic is actually load-balanced over all the links from the leaf to the spine to the leaf.
So let us say welcome to BGP in our data center offering underlay reachability.
But which flavor of BGP would we run between our spines and our leafs?
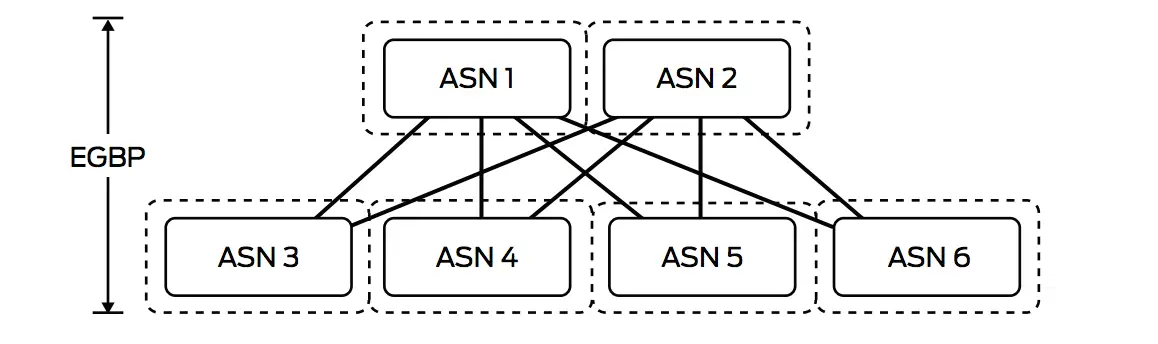
Would we run EBGP where each TOR is in different AS or would we run IBGP were all of the spines and leafs are in the same AS or would we run mix between them where I divide my DC into zones each zone has its own AS.
These a design decisions and it is debatable, technically the 3 options of BGP would work in all cases but some vendor and network consultant prefer one solution over the other, Juniper, for example, recommend the EBGP solution, in here lets focus in the 2 main option all IBGP or all EBGP.
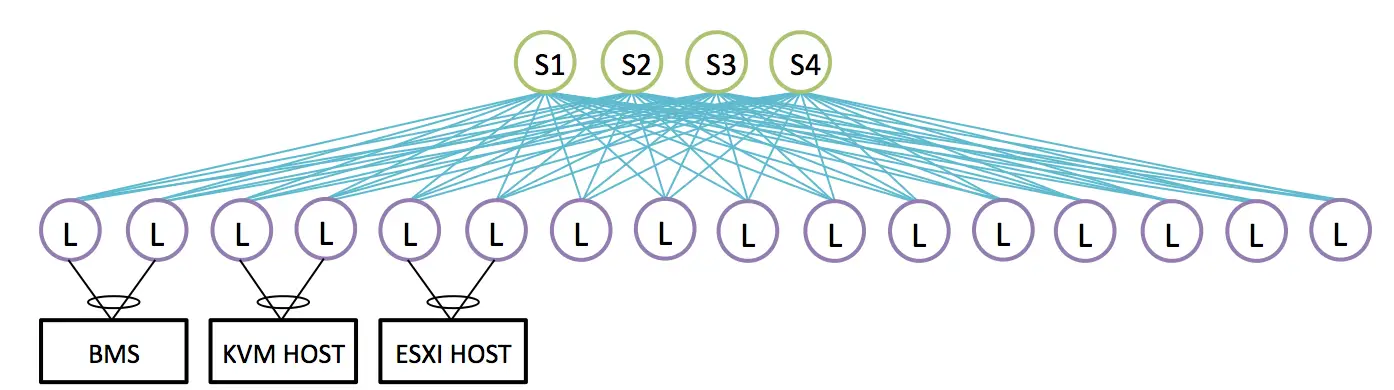
Before you look at the difference between them, we need to consider the multi-home servers where a server (or access switch in some DC) would be connected to two leaves (two TOR) and we want to run active-active to offer redundancy and load balancing. For these servers we need to make sure the traffic is load balanced over the whole path, this kind of multi-home servers plays important role in your IBGP or EBGP design.
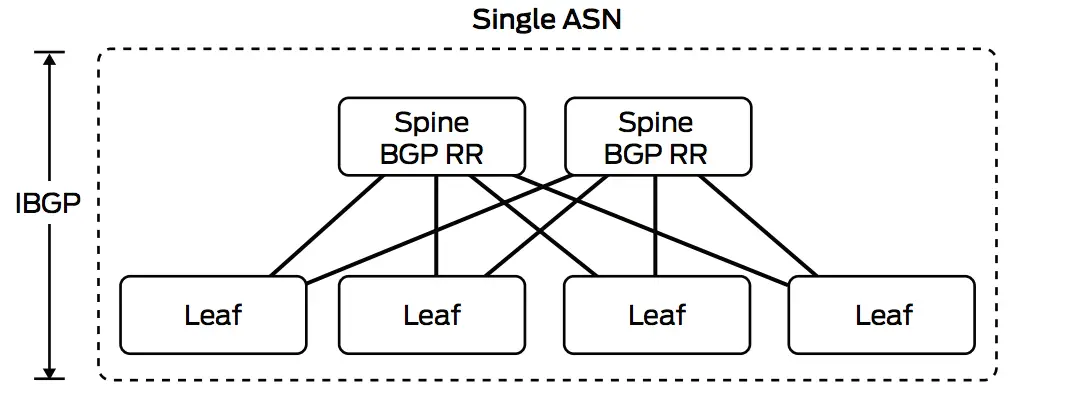
So if we run IBGP for sure it won't any make sense to run full mesh IBGP session between all of your spine and leafs, for example in 4 spines and 200 leaves we would need 203 IBGP session for each leaf!! What about bigger DC even more sessions.
As server provide do, we would run route reflector ( don't think of confederation) were most commonly you make your spines as route reflector and recommended to make all of your spines as RR or add the add-path feature which is relatively new features as BGP only send the best path, would we make all the spines RR or only 2 is enough and why?
Let's say that S1,S2 are route reflectors and we want to make sure the traffic between the BMS and the KVM host is load balanced, then If the two Leafs attached to the BMS server would advertise the IP address of the BMS to S1,S2 then S1 and S2 would reflect this update to all the leafs plus S3,S4 so the two leafs attached to KVM, can you spot the issue in here ?
When the traffic toward BMS reached S3, S4 they will only have one next hope (one of the leafs of BMS) why? Because S1 and S2 would only reflect the best route so only one next hop would be sent. One solution would be the add-path feature which allows the RR to send more than one route so more than one next-hop and we would have proper load-balancing.
Another question would be asked for the IBGP implementation what about the peering address? Would be the loopback as common practices for IBGP or the physical IP address, in that case, the spine-leaf interface IP address?
If we peer with the loopback then you have to run IGP to provide loopback reachable, because BGP is kind of next hop protocol, not an exit interface. were BGP runs all of its magic to provide you next-hop then leave it to another protocol (IGP in most cases), so we technically did not get rid of IGP completely, plus peering with the loopback IP doesn’t offer that much of benefits in our topology.
So for the IBGP solution it is better to make your spine as RR, either all of them if we have like 4 spines but you if you grow more than that then use the add-path for better load balancing.
Another concept in here which is shared in the IBGP & EBGP solution is the interface speed in between the spine and leaf, it has to be same speed because the nature of BGP doesn’t consider the speed of the interface without adjusting that (metric or cost community) but adjusting it just and more administration headache, normally it is not recommended solution but I have seen some discussion about doubling the link between spine and leaf by adding another line so instead of 10G or 40G it would be 20G or 80G and to simplify the configuration the two physical interface would be bundled in one ether-channel/aggregate-Ethernet but in case of one interface of the bundle fail then BGP wont feel that and BGP would steel consider this 10G interface (after one physical link failed) as if it is 20G because BGP by nature doesn’t consider the link speed, one solution for that bundle issue is min-links feature for the ether-channel/aggregate-Ethernet (all vendors have it).
The other solution would be EBGP where each spine or leaf would be in different AS, you might choose the private range 64512 – 65534 so you have around 1000 which is enough number to cover 1000 TOR in one segment, some other design uses the same AS for all the leafs then use AS-override or allow-in feature.
All of these solutions would do the job.
You would run EBGP sessions only over the physical IP address of the interface so no need to run IGP at all.
Now you think of the configuration that creates this huge number of BGP sessions?
Yes, you have to configure all of that, but you can do it just one time as you script it :) so basically create a script that takes these inputs.
- Number of spines
- Number of leafs
- The AS number range
- The subnet to be used for the IP address for all the Spine-leaf interface
- Any other parameter you would like to add (BFD for example)
In fact, there are many scripts exists that can do so for you, plus some vendor tools for that. Until Next Post.
Check Also

